java-note[0]-JAVA源码-基本类型
String & StringBuffer & StringBuilder
-
String
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* 使用 char 数组作为数据存储(在jdk1.9改用byte[]。优化存储空间占用,一个char占用两个byte空间)
* 使用 final 修饰,说明value[]不可变。
*/
private final char value[];
/**
* 如果是通过构造函数创建字符串类型,那么值是通过传入的魔法值进行获取的,也就是说当前实例的value是常量池的引用。
* 所以说 使用 `new String("123")` 这种方式会产生两个字符串,一个在常量池中,一个在堆里。
*/
public String() {
this.value = "".value;
}
public String(String original) {
this.value = original.value;
this.hash = original.hash;
} -
StringBuffer
继承父类 AbstractStringBuilder value 与 String 不同,是没有被 final 修饰的。所以在连续拼接时,不会像 String 那样需要创建新的对象。在效率上更高。(效率提升来自于省略了对象实例化过程)
初始 capacity = 16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public StringBuilder append(String str) {
super.append(str);
return this;
}
char[] value;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
} -
StringBuilder
相对于StringBuilder,他的一系列方法都使用 synchronized 进行加锁控制。
使用 toStringCache 作为 toString 方法的缓存器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private transient char[] toStringCache;
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
/**
* 没被修改的时候, 就可以直接把toStringCache作为new String的参数. 然后把这个String返回就行了。
* 也就是cache有效的时候, 就不必进行arraycopy的复制操作. cache失效了才进行arraycopy的复制操作。
*/
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
Collection
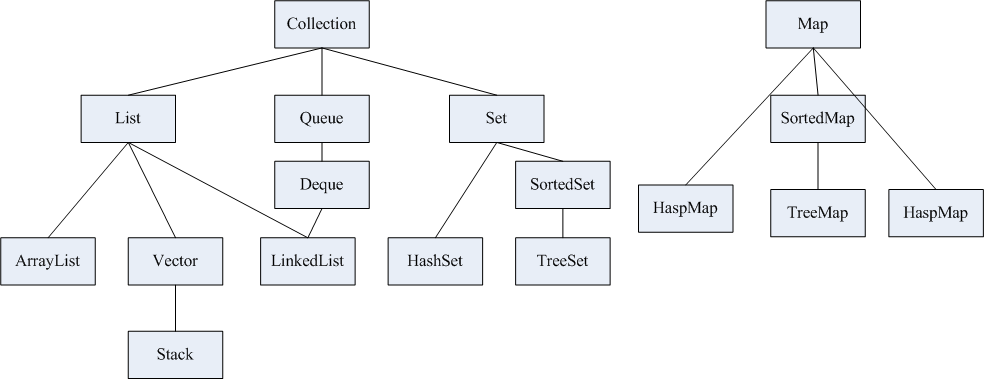 java基本集合框架
java基本集合框架
List
ArrayList
1 | /** |
LinkedList
1 | public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable |
LinkedList 实现了 List 和 Deque 接口,所以可以作为列表和双端队列使用。
1 | transient int size = 0; |
Vector
与 ArrayList 相似,但是 Vector 是同步的(它的public方法都使用了 synchronized 修饰)。所以说 Vector 是线程安全的动态数组。它的操作与 ArrayList 几乎一样。
Stack
1 | /** |
Iterator 接口 & ListIterator 接口
Iterator 是一个接口,它是集合的迭代器。集合可以通过 Iterator 去遍历集合中的元素。
1 | // 判断集合里是否存在下一个元素。如果有,hasNext() 方法返回 true |
ListIterator 接口继承 Iterator 接口,提供了专门操作 List 的方法。
1 | // 判断集合里是否存在上一个元素。如果有,hasPrevious() 方法返回 true |
以上两个接口相比较会发现,ListIterator 增加了向前迭代的功能( Iterator 只能向后迭代),ListIterator 还可以通过 add() 方法向 List 集合中添加元素(Iterator 只能删除元素)。
Queue
LinkedList
如上
ArrayDeque
1 | // 底层是Object数组 |
PriorityQueue
优先队列PriorityQueue是Queue接口的实现,可以对其中元素进行排序,可以放基本数据类型的包装类(如:Integer,Long等)或自定义的类对于基本数据类型的包装器类,优先队列中元素默认排列顺序是升序排列但对于自己定义的类来说,需要自己定义比较器(Comparator)。
Set
HashSet
1 | public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{ |
TreeSet & SortedSet
reeSet时SortedSet接口的实现类,TreeSet可以保证元素处于排序状态,它采用红黑树的数据结构来存储集合元素。
TreeSet支持两种排序方法:自然排序和定制排序,默认采用自然排序。
1 | // NavigableMap接口继承了SortedMap |
Map
HashMap
1 | public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { |
LinkedHashMap
1 | /** |
HashTable
数据结构与HashMap一致,所有公共方法都使用synchronized修饰。但它是一个被抛弃的类,它的hash算法以及链表的结构没有像JDK1.8的HashMap那样优化。
TreeMap
1 | /** |
