ElasticSearch[5]-正片:映射(mapping)&分词(analysis)前置
定义
- 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string,number,booleans,date等)。
- 分析(analysis)机制用于进行全文文本(Full Text)的分词,以建立供搜索用的反向索引。
映射 & 分词
ElasticSearch 会对每一个type进行mapping:通过以下指令可以查看
1 | GET /{index}/_mapping/{type}/ |
可以看出 ES对每一个字段进行猜想动态生成了字段和类型的映射关系。比如date字段的类型date,而在_all字段中date的值则是string。那么问题来了,假如使用以下方式进行检索:
1 | GET /_search?q=2019 |
将会得到不一样的结果,因为date类型和string类型的索引方式是不一样的,索引会导致查询结果不一致。
你会期望每一种核心数据类型(strings, numbers, booleans及dates)以不同的方式进行索引,而这点也是现实:在Elasticsearch中他们是被区别对待的。
但是更大的区别在于确切值(exact values)(比如 string 类型)及全文文本(full text)之间。
这两者的区别才真的很重要 - 这是区分搜索引擎和其他数据库的根本差异。
——《ES权威指南(第三版)》
确切值(Exact values) & 全文文本(Full text)
Elasticsearch 中的数据可以大致分为两种类型:确切值 及 全文文本。
确切值 类似于一种结构化的数据值,(是什么就是什么,类似于equals),所以的大小写区别、前缀一致等形式的"等价"都是不成立了。
而 全文本 则是一种类似与 非结构化的数据值。(实际上是一种高度结构化的数据)
因此,对于确切值来说,他的查询时很简单的,要么匹配,要么不匹配。不会像全文本一样需要对其进行语言的分析以及相关度高低来进行评判。
为此,ElasticSearch 使用了全文本分析(analyzes),然后建立 倒排索引。
倒排索引
倒排索引由文档中出现的唯一的单词列表,以及对于每一个单词在文档中的位置组成。
实例:
例如,我们有两个文档,每个文档 content 字段包含:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先切分每个文档的 content 字段为单独的单词(我们把它们叫做词(terms)或者表征(tokens))(译者注:关于 terms 和 tokens 的翻译比较生硬,只需知道语句分词后的个体叫做这两个。),把所有的唯一词放入列表并排序,结果是这个样子的:

现在,如果我们想搜索 “quick brown” ,我们只需要找到每个词在哪个文档中出现即可:
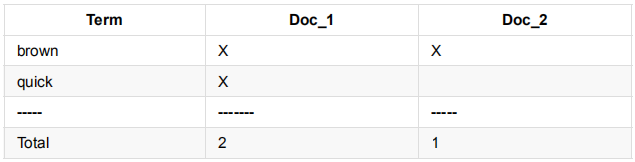
但是这里依然存在一些问题,之前说的全文搜索应当是一种符合语义的,所以对于其中一些单词的语义、词性的相似度进行比较。所以考虑到这些因素之后的相似度比较就不再那么单纯了。
此时就需要一个标准化的过程:分词((analysis))
