并发[3]-线程池怎么玩
线程池的基本使用
1 | package com.theembers.threadpool; |
线程池的定义和优点
线程池是与工作队列密切相关的,其中在工作队列中保存了所有等待执行的任务。工作线程的任务很简单:从工作队列中获取一个任务,执行任务,然后返回线程池并等待下一个任务。
在线程池中执行任务 比 为每个线程分配一个任务 优势更多。通过重用现有的线程而不是创建线程,可以在处理多个请求时分摊在线程创建和销毁过程中产生的巨大开销。另一个额外的好处是,当请求到达时,工作线程通常已经存在,因此不会由于等待创建线程而延迟任务的执行,从而提高了响应性。通过适当的调整线程池的大小,可以创建足够的线程以便使处理器保持忙碌状态,同时还可以防止过多线程相互竞争资源而使应用程序耗尽内存或失败。
核心思想:线程的创建和销毁需要很大的开销,线程池用来维护并管理线程以减少开销。
线程池的工作流程
- 默认情况下,创建完线程池后并不会立即创建线程, 而是等到有任务提交时才会创建线程来进行处理。(除非调用 prestartCoreThread 或 prestartAllCoreThreads 方法)
- 当线程数小于核心线程数时,每提交一个任务就创建一个线程来执行,即使当前有线程处于空闲状态,直到当前线程数达到核心线程数。
- 当前线程数达到核心线程数时,如果这个时候还提交任务,这些任务会被放到队列里,等到线程处理完了手头的任务后,会来队列中取任务处理。
- 当前线程数达到核心线程数并且队列也满了,如果这个时候还提交任务,则会继续创建线程来处理,直到线程数达到最大线程数。
- 当前线程数达到最大线程数并且队列也满了,如果这个时候还提交任务,则会触发饱和策略。
- 如果某个线程的控线时间超过了 keepAliveTime,那么将被标记为可回收的,并且当前线程池的当前大小超过了核心线程数时,这个线程将被终止。
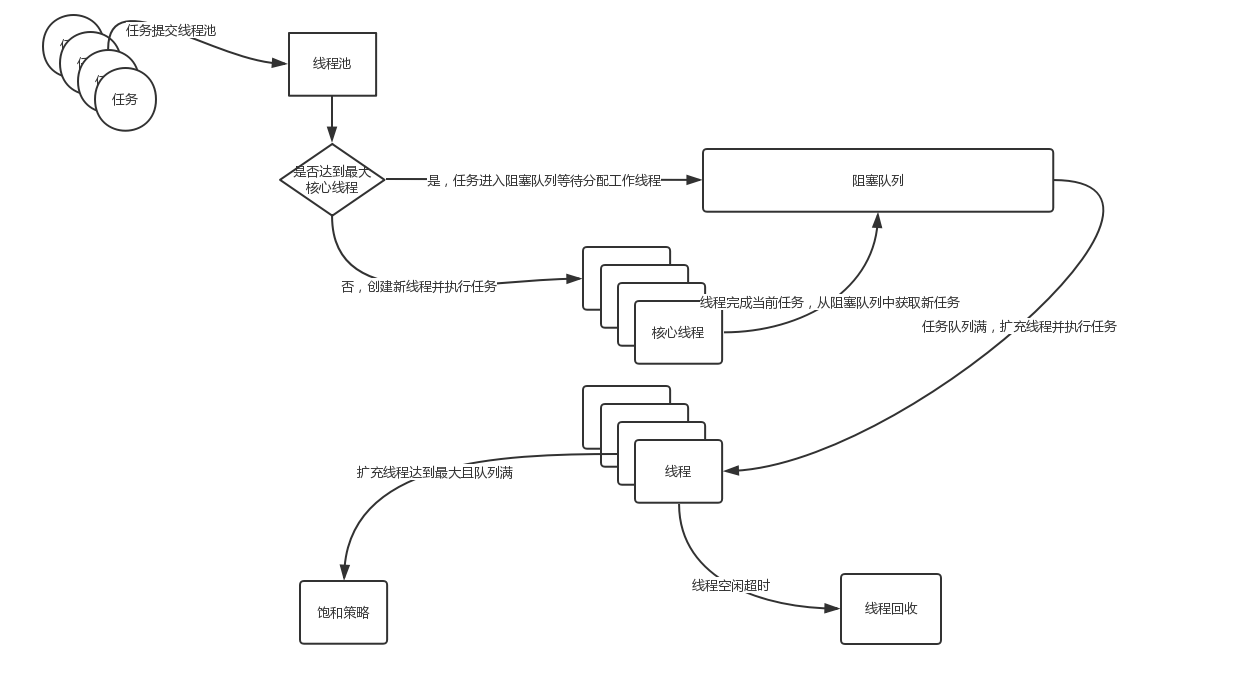 线程池工作流程.png
线程池工作流程.png
工作队列(阻塞队列)
如果新请求的到达速率超过了线程池的处理速率,那么新到来的请求将累积起来。在线程池中,这些请求会在一个由 Executor 管理的 Runnable 队列中等待,而不会像线程那样去竞争 CPU 资源。常见的工作队列有以下几种,前三种用的最多。
- ArrayBlockingQueue:列表形式的工作队列,必须要有初始队列大小,有界队列,先进先出。
- LinkedBlockingQueue:链表形式的工作队列,可以选择设置初始队列大小,有界/无界队列,先进先出。
- SynchronousQueue:SynchronousQueue 不是一个真正的队列,而是一种在线程之间移交的机制。要将一个元素放入 SynchronousQueue 中, 必须有另一个线程正在等待接受这个元素. 如果没有线程等待,并且线程池的当前大小小于最大值,那么 ThreadPoolExecutor 将创建 一个线程, 否则根据饱和策略,这个任务将被拒绝。使用直接移交将更高效,因为任务会直接移交 给执行它的线程,而不是被首先放在队列中, 然后由工作线程从队列中提取任务. 只有当线程池是无解的或者可以拒绝任务时,SynchronousQueue 才有实际价值。
说白了就是个 0 容量的队列,核心线程饱和后直接将任务移交给拓展线程。
- PriorityBlockingQueue:优先级队列,有界队列,根据优先级来安排任务,任务的优先级是通过自然顺序或 Comparator(如果任务实现了 Comparator)来定义的。
- DelayedWorkQueue:延迟的工作队列,无界队列。
饱和策略(拒绝策略)
当有界队列被填满后,饱和策略开始发挥作用。ThreadPoolExecutor 的饱和策略可以通过调用 setRejectedExecutionHandler 来修改。(如果某个任务被提交到一个已被关闭的 Executor 时,也会用到饱和策略)。饱和策略有以下四种,一般使用默认的 AbortPolicy。
- AbortPolicy:中止策略。默认的饱和策略,抛出未检查的 RejectedExecutionException。调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
- DiscardPolicy:抛弃策略。当新提交的任务无法保存到队列中等待执行时,该策略会悄悄抛弃该任务。
- DiscardOldestPolicy:抛弃最旧的策略。当新提交的任务无法保存到队列中等待执行时,则会抛弃下一个将被执行的任务,然后尝试重新提交新的任务。(如果工作队列是一个优先队列,那么“抛弃最旧的”策略将导致抛弃优先级最高的任务,因此最好不要将“抛弃最旧的”策略和优先级队列放在一起使用)。
- CallerRunsPolicy:调用者运行策略。该策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者(调用线程池执行任务的主线程),从而降低新任务的流程。它不会在线程池的某个线程中执行新提交的任务,而是在一个调用了 execute 的线程中执行该任务。当线程池的所有线程都被占用,并且工作队列被填满后,下一个任务会在调用 execute 时在主线程中执行(调用线程池执行任务的主线程)。由于执行任务需要一定时间,因此主线程至少在一段时间内不能提交任务,从而使得工作者线程有时间来处理完正在执行的任务。在这期间,主线程不会调用 accept,因此到达的请求将被保存在 TCP 层的队列中。如果持续过载,那么 TCP 层将最终发现它的请求队列被填满,因此同样会开始抛弃请求。当服务器过载后,这种过载情况会逐渐向外蔓延开来——从线程池到工作队列到应用程序再到 TCP 层,最终达到客户端,导致服务器在高负载下实现一种平缓的性能降低。
线程工厂
每当线程池需要创建一个线程时,都是通过线程工厂方法来完成的。在 ThreadFactory 中只定义了一个方法 newThread,每当线程池需要创建一个新线程时都会调用这个方法。Executors 提供的线程工厂有两种,一般使用默认的,当然如果有特殊需求,也可以自己定制。
- DefaultThreadFactory:默认线程工厂,创建一个新的、非守护的线程,并且不包含特殊的配置信息。
- PrivilegedThreadFactory:通过这种方式创建出来的线程,将与创建 privilegedThreadFactory 的线程拥有相同的访问权限、 AccessControlContext、ContextClassLoader。如果不使用 privilegedThreadFactory, 线程池创建的线程将从在需要新线程时调用 execute 或 submit 的客户程序中继承访问权限。
- 自定义线程工厂:可以自己实现 ThreadFactory 接口来定制自己的线程工厂方法。
